[Research] PageRank의 소규모 데이터 적용과 추천 시스템의 구현 과정
글쓴이 : MovingJu
Abstract
소규모의 데이터를 활용하는 것은 쉽지 않다.
특히, 그 데이터에서 의미를 끌어내는 것을 넘어 활용해야 하는 경우 많은 어려움이 동반된다.
본 글에선 관광데이터에 PageRank 시스템을 활용해 추천 시스템을 구현한 사례를 탐구하고자 한다.
해당 사례는 적은 정보를 가진 데이터셋에도 불구하고 좋은 추천 시스템 구현을 위해 Multi-data Model을 이용했다는 점에 의의가 있다.
Introduce
Datasets
-
데이터셋 링크 : 공공데이터포털
-
활용한 데이터 샘플 :
{
"response": {
"header": {
"resultCode": "0000",
"resultMsg": "OK"
},
"body": {
"items": {
"item": [
{
"addr1": "부산광역시 사하구 낙동남로 1240 (하단동)",
"addr2": "",
"contentid": "127974",
"firstimage": "http://tong.visitkorea.or.kr/cms/resource/21/3497121_image2_1.jpg",
"firstimage2": "http://tong.visitkorea.or.kr/cms/resource/21/3497121_image3_1.jpg",
"lDongRegnCd": "26",
"lDongSignguCd": "380",
"lclsSystm1": "NA",
"lclsSystm2": "NA04",
"lclsSystm3": "NA040500",
...
}
]
},
"numOfRows": 1,
"pageNo": 1,
"totalCount": 3
}
}
}
lDongRegnCd, lDongSigunguCd는 각각 법정 분류 시 / 군구 코드를 나타낸다.
lclsSystm1-3은 관광지의 타입을 나타내는 대, 중, 소 분류 코드로, 이후 추천 시스템에서 활용한다.
해당 형태의 관광지가 대략 50,000개 정도 존재하며, 이미지의 존재 여부 등이 제각각이다.
관광지 타입 코드 정보와 이미지 정보가 거의 관광지 정보의 대부분이므로, 장소 하나의 정보가 적다.
Data Flow of Model
해당 추천 모델은 2025 관광데이터공모전 의 팀 PICK AND GO 백엔드 추천 서버에 활용되었다.
따라서, 백엔드 추천 서버의 데이터 흐름을 모식화 했다.
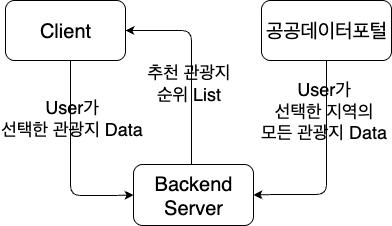
Fig. 0
위 그림의 User가 선택한 모든 관광지를 받아올 때, 수백 - 수천개의 관광지를 불러와야 한다.
이와 동시에 각 관광지들이 유저가 고른 관광지와 얼마나 비슷한지 수치화 하고, 순위를 매긴다.
이 이후부터 관광지 순위에 유저의 관광지 코드 선호도와 관광지 이미지를 어떻게 반영했는지 탐구할 것이다.
부가적으로, 비동기 처리하며 성능을 600배 이상 향상시킨 기능 클래스는 다른 Research에서 보고하겠다.
PageRank
추천 모델을 정확히 파악하기 위해선 현대 검색 알고리즘의 핵심인 PageRank 시스템에 대해 이해해야 한다.
임의의 웹 페이지 A, B, C, D에 대해 다음과 같은 참조 관계가 있다고 하자.
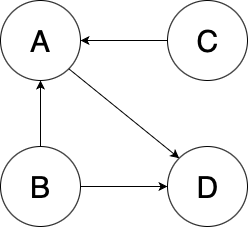
\[\begin{pmatrix} & A & B & C & D \\ A & 1 & 0 & 1 \\ B & 1 & 0 & 0 \\ C & 0 & 1 & 0 \\ D & 0 & 0 & 1 \end{pmatrix}\] \[\begin{pmatrix} 1 & 2 \\ 3 & 4 \end{pmatrix}\]Fig. 1
이상.
Comments